
Un écouteur traducteur – ou oreillette traductrice – est un appareil Bluetooth qui traduit une conversation orale en temps réel, en moins d’une seconde sur les meilleurs modèles, via une chaîne : micro → reconnaissance vocale → traduction IA → restitution audio dans l’oreille.
L’erreur la plus courante : croire que l’oreillette embarque un cerveau autonome. En réalité, elle joue le rôle de microphone et de haut-parleur – le pipeline logiciel, lui, tourne sur votre téléphone et dans le cloud. C’est ce pipeline qui explique tout : la latence, les langues disponibles, pourquoi parler lentement aide. Voici comment ça fonctionne, concrètement.
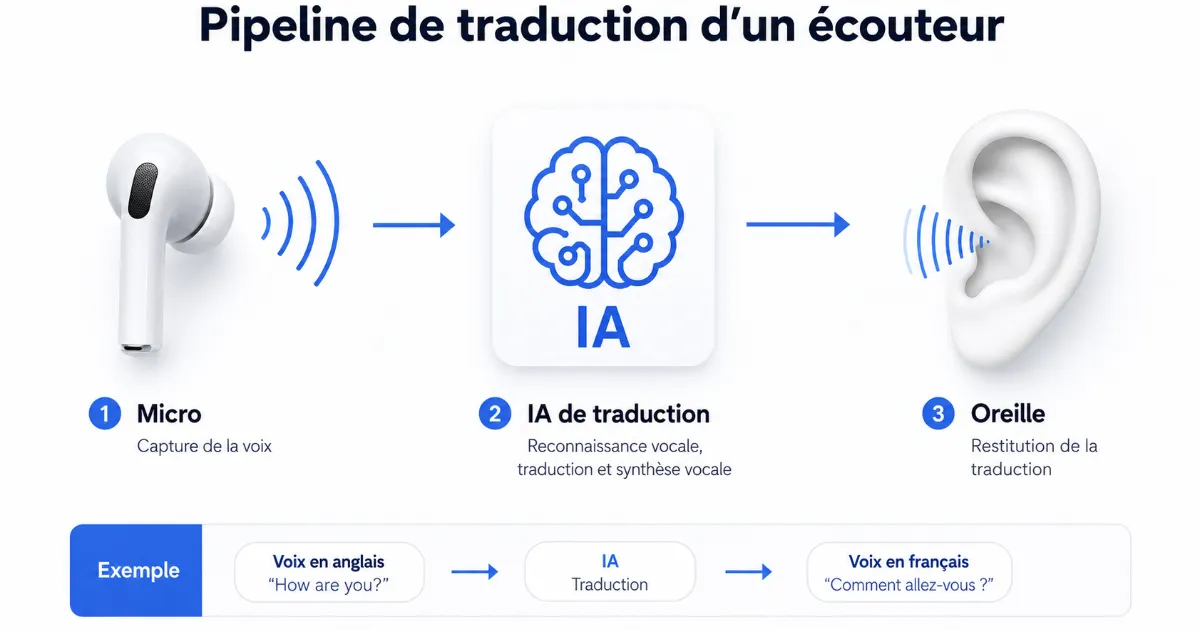
Étape 1 – Le microphone capte la voix (et filtre le bruit)
Tout commence par le son. L’écouteur traducteur est équipé d’un ou plusieurs microphones directionnels dont le rôle est de capturer la voix de votre interlocuteur et d’isoler ce signal du bruit ambiant.
Les modèles entrée de gamme ont un seul micro orienté vers l’avant. Les versions plus élaborées combinent deux ou trois microphones avec un algorithme de réduction de bruit active : ils comparent les signaux reçus et soustraient le bruit constant (moteur d’avion, foule, climatisation) pour ne garder que la parole.
Ce que ça change dans la pratique
Plus le micro est précis, plus la reconnaissance vocale qui suit travaille sur un signal propre. Un environnement bruyant – restaurant, salon professionnel, rue – dégrade la précision de toute la chaîne. Ce n’est pas un problème logiciel, c’est la physique du son.
Étape 2 – La reconnaissance vocale (ASR) convertit le son en texte
Le signal audio capturé est transmis à un moteur de reconnaissance automatique de la parole (ASR – Automatic Speech Recognition). Ce composant transforme les ondes sonores en texte numérique.
Dans la plupart des écouteurs traducteurs, cette étape se passe dans le cloud : l’audio est envoyé via Bluetooth à l’application mobile, qui le transmet aux serveurs du fabricant. Les modèles ASR modernes sont entraînés sur des centaines de milliers d’heures de voix humaines – accents, débits, registres.
ASR en ligne vs. ASR hors-ligne
En mode en ligne, l’ASR utilise un modèle complet hébergé sur serveur. En mode hors-ligne, un modèle allégé est téléchargé localement sur le smartphone. Ce modèle réduit est moins précis sur les accents régionaux et les mots rares, mais il fonctionne sans réseau.
Étape 3 – La traduction neuronale (NMT) transforme le texte
Le texte produit par l’ASR est envoyé au moteur de traduction automatique neuronale (NMT – Neural Machine Translation). C’est l’IA proprement dite : elle ne traduit pas mot à mot, elle reconstitue le sens global de la phrase dans la langue cible.
Les NMT modernes ne traduisent pas mot à mot : ils lisent la phrase entière avant de produire la version dans l’autre langue. C’est pour ça qu’ils gèrent mieux les tournures idiomatiques et les changements de registre qu’un vieux dictionnaire en ligne.
À noter : la qualité de la traduction dépend du volume de données d’entraînement disponibles pour chaque paire de langues. Anglais-français est excellent. Wolof-hindi, beaucoup moins.
Pourquoi les dialectes posent problème
Un modèle entraîné sur l’espagnol castillan traduit moins bien l’espagnol argentin. L’arabe marocain (darija) diffère suffisamment de l’arabe classique pour provoquer des erreurs. Ce n’est pas une promesse non tenue – c’est une limite réelle de la technologie actuelle, que les meilleures fiches produit devraient mentionner.
Étape 4 – La synthèse vocale (TTS) restitue le son dans votre oreille
Le texte traduit est transmis au moteur de synthèse vocale (TTS – Text-to-Speech), qui le convertit en audio et le diffuse dans votre oreillette. La voix synthétique est générée en temps réel.
Sur les grandes langues (anglais, espagnol, mandarin), les voix synthétiques actuelles sont bluffantes. Sur les langues moins dotées, le résultat est plus robotique – mais suffisant pour une conversation. Le résultat arrive dans votre oreille en quelques fractions de seconde après la fin de la synthèse.

Le rôle du smartphone dans la chaîne
Un écouteur traducteur n’est pas autonome. Le traitement se passe dans l’application mobile, pas dans l’écouteur. L’écouteur capte et restitue le son – le téléphone envoie, reçoit et orchestre.
Le smartphone reçoit l’audio, le transmet aux serveurs, récupère la traduction et la renvoie à l’écouteur. Cette architecture explique deux choses :
- La latence dépend de la connexion réseau, pas seulement de l’appareil.
- Une application obsolète ou un serveur surchargé dégradent les performances, même avec un écouteur de qualité.
| Mode | Traitement | Langues | Précision |
|---|---|---|---|
| En ligne (Wi-Fi / 4G) | Cloud (serveurs fabricant) | 40 à 150+ langues | Élevée sur les grandes langues |
| Hors-ligne (sans réseau) | Local (smartphone) | 10 à 20 langues max | Réduite sur accents et mots rares |
| Mode texte affiché | Cloud + affichage écran | Identique au mode en ligne | Identique, avec lecture visuelle |
Pourquoi la latence varie d’un écouteur traducteur à l’autre
La latence totale est la somme de quatre délais : capture audio → transmission Bluetooth → aller-retour serveur → synthèse et restitution. Sur une bonne connexion 4G ou Wi-Fi stable, les meilleurs modèles atteignent 0,5 à 1 seconde. Sur une connexion instable, ce délai monte facilement à 3 secondes.
Ce qui fait varier la latence d’un appareil à l’autre :
- La qualité du module Bluetooth (version 5.0 vs. 4.2)
- La proximité géographique des serveurs du fabricant
- La taille du modèle NMT utilisé
Un délai de 1 à 1,5 seconde est imperceptible en conversation calme. À 3 secondes, les tours de parole deviennent inconfortables.
Ce qu’un écouteur traducteur ne sait pas encore faire
Le bruit de fond reste le premier ennemi
Les modèles ASR progressent vite, mais un environnement très bruyant – fête de rue, salle de concert – peut encore perturber la reconnaissance. Parler légèrement plus lentement qu’en conversation normale aide – l’effet est perceptible, même si les chiffres avancés par les fabricants sont à prendre avec du recul.
Confidentialité : vos phrases passent par des serveurs
En mode en ligne, l’audio ou le texte transcrit transite vers les serveurs du fabricant. La plupart des acteurs sérieux appliquent le chiffrement en transit et ne stockent pas les conversations, mais il est utile de le savoir avant d’utiliser un écouteur traducteur dans des réunions sensibles. Le mode hors-ligne règle ce point – au prix d’une couverture de langues réduite.
À retenir
En pratique : votre voix entre dans le micro, elle ressort traduite dans votre oreille quelques secondes plus tard. Entre les deux, quatre étapes – capture, transcription, traduction, synthèse – dont la plupart se passent sur des serveurs distants. Les performances dépendent de la qualité du signal capté, de la vitesse de la connexion et des langues en jeu.
La latence réelle se situe entre 0,5 et 3 secondes selon les conditions. Le mode hors-ligne fonctionne – sur un périmètre de langues réduit. Les dialectes et accents régionaux restent les vrais points aveugles de la technologie.
Si vous cherchez un modèle qui minimise la latence en priorité, les écouteurs traducteurs instantanés sont conçus spécifiquement pour la fluidité de conversation en temps réel.